
{kind=link}
Amazon Redshift helps querying knowledge saved utilizing Apache Iceberg tables, an open desk format that simplifies administration of tabular knowledge residing in knowledge lakes on Amazon Easy Storage Service (Amazon S3). Amazon S3 Tables delivers the primary cloud object retailer with built-in Iceberg assist and streamlines storing tabular knowledge at scale, together with continuous desk optimizations that assist enhance question efficiency. Amazon SageMaker Lakehouse unifies your knowledge throughout S3 knowledge lakes, together with S3 Tables, and Amazon Redshift knowledge warehouses, helps you construct highly effective analytics and synthetic intelligence and machine studying (AI/ML) functions on a single copy of information, querying knowledge saved in S3 Tables with out the necessity for complicated extract, rework, and cargo (ETL) or knowledge motion processes. You may reap the benefits of the scalability of S3 Tables to retailer and handle massive volumes of information, optimize prices by avoiding further knowledge motion steps, and simplify knowledge administration by way of centralized fine-grained entry management from SageMaker Lakehouse.
On this put up, we reveal how one can get began with S3 Tables and Amazon Redshift Serverless for querying knowledge in Iceberg tables. We present how one can arrange S3 Tables, load knowledge, register them within the unified knowledge lake catalog, arrange fundamental entry controls in SageMaker Lakehouse by way of AWS Lake Formation, and question the information utilizing Amazon Redshift.
Observe – Amazon Redshift is only one choice for querying knowledge saved in S3 Tables. You may study extra about S3 Tables and extra methods to question and analyze knowledge on the S3 Tables product web page.
Resolution overview
On this resolution, we present how one can question Iceberg tables managed in S3 Tables utilizing Amazon Redshift. Particularly, we load a dataset into S3 Tables, hyperlink the information in S3 Tables to a Redshift Serverless workgroup with acceptable permissions, and eventually run queries to investigate our dataset for traits and insights. The next diagram illustrates this workflow.
On this put up, we are going to stroll by way of the next steps:
- Create a desk bucket in S3 Tables and combine with different AWS analytics providers.
- Arrange permissions and create Iceberg tables with SageMaker Lakehouse utilizing Lake Formation.
- Load knowledge with Amazon Athena. There are other ways to ingest knowledge into S3 Tables, however for this put up, we present how we are able to shortly get began with Athena.
- Use Amazon Redshift to question your Iceberg tables saved in S3 Tables by way of the auto mounted catalog.
Conditions
The examples on this put up require you to make use of the next AWS providers and options:
Create a desk bucket in S3 Tables
Earlier than you should utilize Amazon Redshift to question the information in S3 Tables, it’s essential to first create a desk bucket. Full the next steps:
- Within the Amazon S3 console, select Desk buckets on the left navigation pane.
- Within the Integration with AWS analytics providers part, select Allow integration when you haven’t beforehand set this up.
This units up the combination with AWS analytics providers, together with Amazon Redshift, Amazon EMR, and Athena.

After a couple of seconds, the standing will change to Enabled.

- Select Create desk bucket.
- Enter a bucket identify. For this instance, we use the bucket identify
redshifticeberg. - Select Create desk bucket.

After the S3 desk bucket is created, you’ll be redirected to the desk buckets listing.

Now that your desk bucket is created, the following step is to configure the unified catalog in SageMaker Lakehouse by way of the Lake Formation console. This can make the desk bucket in S3 Tables accessible to Amazon Redshift for querying Iceberg tables.
Publishing Iceberg tables in S3 Tables to SageMaker Lakehouse
Earlier than you’ll be able to question Iceberg tables in S3 Tables with Amazon Redshift, it’s essential to first make the desk bucket accessible within the unified catalog in SageMaker Lakehouse. You are able to do this by way of the Lake Formation console, which helps you to publish catalogs and handle tables by way of the catalogs characteristic, and assign permissions to customers. The next steps present you how one can arrange Lake Formation so you should utilize Amazon Redshift to question Iceberg tables in your desk bucket:
- If you happen to’ve by no means visited the Lake Formation console earlier than, it’s essential to first accomplish that as an AWS consumer with admin permissions to activate Lake Formation.
You can be redirected to the Catalogs web page on the Lake Formation console. You will notice that one of many catalogs accessible is the s3tablescatalog, which maintains a catalog of the desk buckets you’ve created. The next steps will configure Lake Formation to make knowledge within the s3tablescatalog catalog accessible to Amazon Redshift.

Subsequent, you want to create a database in Lake Formation. The Lake Formation database maps to a Redshift schema.
- Select Databases underneath Information Catalog within the navigation pane.
- On the Create menu, select Database.

- Enter a reputation for this database. This instance makes use of
icebergsons3. - For Catalog, select the desk bucket that you simply created. On this instance, the identify may have the format
:s3tablescatalog/redshifticeberg - Select Create database.

You can be redirected on the Lake Formation console to a web page with extra details about your new database. Now you’ll be able to create an Iceberg desk in S3 Tables.
- On the database particulars web page, on the View menu, select Tables.

This can open up a brand new browser window with the desk editor for this database.
- After the desk view masses, select Create desk to start out creating the desk.

- Within the editor, enter the identify of the desk. We name this desk
examples. - Select the catalog (
:s3tablescatalog/redshifticeberg icebergsons3).

Subsequent, add columns to your desk.
- Within the Schema part, select Add column, and add a column that represents an ID.

- Repeat this step and add columns for added knowledge:
category_id(lengthy)insert_date(date)knowledge(string)
The ultimate schema appears like the next screenshot.

- Select Submit to create the desk.
Subsequent, you want to arrange a read-only permission so you’ll be able to question Iceberg knowledge in S3 Tables utilizing the Amazon Redshift Question Editor v2. For extra data, see Conditions for managing Amazon Redshift namespaces within the AWS Glue Information Catalog.
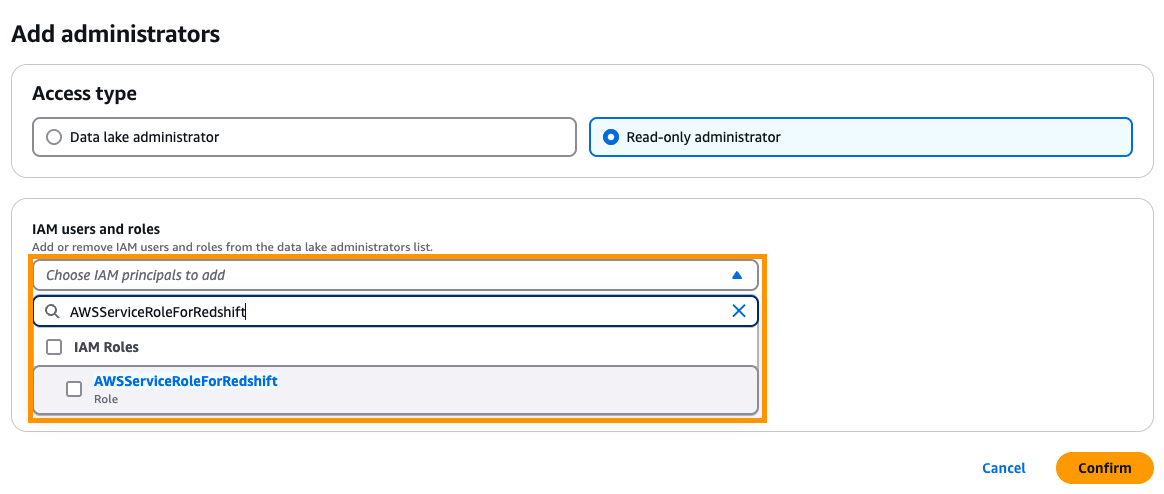
- Underneath Administration within the navigation pane, select Administrative roles and duties.
- Within the Information lake directors part, select Add.

- For Entry sort, choose Learn-only administrator.
- For IAM customers and roles, enter
AWSServiceRoleForRedshift.
AWSServiceRoleForRedshift is a service-linked function that’s managed by AWS.
- Select Verify.
You will have now configured SageMaker Lakehouse utilizing Lake Formation to permit Amazon Redshift to question Iceberg tables in S3 Tables. Subsequent, you populate some knowledge into the Iceberg desk, and question it with Amazon Redshift.
Use SQL to question Iceberg knowledge with Amazon Redshift
For this instance, we use Athena to load knowledge into our Iceberg desk. That is one choice for ingesting knowledge into an Iceberg desk; see Utilizing Amazon S3 Tables with AWS analytics providers for different choices, together with Amazon EMR with Spark, Amazon Information Firehose, and AWS Glue ETL.
- On the Athena console, navigate to the question editor.
- If that is your first time utilizing Athena, it’s essential to first specify a question outcome location earlier than executing your first question.
- Within the question editor, underneath Information, select your knowledge supply (
AwsDataCatalog). - For Catalog, select the desk bucket you created (
s3tablescatalog/redshifticeberg). - For Database, select the database you created (
icebergsons3).

- Let’s execute a question to generate knowledge for the examples desk. The next question generates over 1.5 million rows akin to 30 days of information. Enter the question and select Run.
The next screenshot reveals our question.

The question takes about 10 seconds to execute.
Now you should utilize Redshift Serverless to question the information.
- On the Redshift Serverless console, provision a Redshift Serverless workgroup when you haven’t already performed so. For directions, see Get began with Amazon Redshift Serverless knowledge warehouses information. On this instance, we use a Redshift Serverless workgroup referred to as
iceberg. - Be sure that your Amazon Redshift patch model is patch 188 or larger.

- Select Question knowledge to open the Amazon Redshift Question Editor v2.

- Within the question editor, select the workgroup you wish to use.
A pop-up window will seem, prompting what consumer to make use of.
- Choose Federated consumer, which can use your present account, and select Create connection.

It’s going to take a couple of seconds to start out the connection. If you’re related, you will notice an inventory of accessible databases.
- Select Exterior databases.
You will notice the desk bucket from S3 Tables within the view (on this instance, that is redshifticeberg@s3tablescatalog).
- If you happen to proceed clicking by way of the tree, you will notice the
examplesdesk, which is the Iceberg desk you beforehand created that’s saved within the desk bucket.

Now you can use Amazon Redshift to question the Iceberg desk in S3 Tables.
Earlier than you execute the question, evaluation the Amazon Redshift syntax for querying catalogs registered in SageMaker Lakehouse. Amazon Redshift makes use of the next syntax to reference a desk: [email protected] or database@namespace".schema.desk.
On this instance, we use the next syntax to question the examples desk within the desk bucket: r[email protected].
Study extra about this mapping in Utilizing Amazon S3 Tables with AWS analytics providers.
Let’s run some queries. First, let’s see what number of rows are within the examples desk.
- Run the next question within the question editor:
The question will take a couple of seconds to execute. You will notice the next outcome.

Let’s attempt a barely extra difficult question. On this case, we wish to discover all the times that had instance knowledge beginning with 0.2 and a category_id between 50–75 with not less than 130 rows. We are going to order the outcomes from most to least.
- Run the next question:
You would possibly see completely different outcomes than the next screenshot due the randomly generated supply knowledge.

Congratulations, you will have arrange and queried Iceberg knowledge in S3 Tables from Amazon Redshift!
Clear up
If you happen to applied the instance and wish to take away the sources, full the next steps:
- If you happen to now not want your Redshift Serverless workgroup, delete the workgroup.
- If you happen to don’t must entry your SageMaker Lakehouse knowledge from the Amazon Redshift Question Editor v2, take away the information lake administrator:
- On the Lake Formation console, select Administrative roles and duties within the navigation pane.
- Take away the read-only knowledge lake administrator that has the
AWSServiceRoleForRedshiftprivilege.
- If you wish to completely delete the information from this put up, delete the database:
- On the Lake Formation console, select Databases within the navigation pane.
- Delete the
icebergsaheaddatabase.
- If you happen to now not want the desk bucket, delete the desk bucket.
- In you wish to deactivate the combination between S3 Tables and AWS analytics providers, see Migrating to the up to date integration course of.
Conclusion
On this put up, we confirmed how one can get began with Amazon Redshift to question Iceberg tables saved in S3 Tables. That is just the start for a way you should utilize Amazon Redshift to investigate your Iceberg knowledge that’s saved in S3 Tables—you’ll be able to mix this with different Amazon Redshift options, together with writing queries that be part of knowledge from Iceberg tables saved in S3 Tables and Redshift Managed Storage (RMS), or implement knowledge entry controls that provide you with fine-granted entry management guidelines for various customers throughout the S3 Tables. Moreover, you should utilize options like Redshift Serverless to routinely choose the quantity of compute for analyzing your Iceberg tables, and use AI to intelligently scale on demand and optimize question efficiency traits in your analytical workload.
We invite you to go away suggestions within the feedback.
In regards to the Authors
 Jonathan Katz is a Principal Product Supervisor – Technical on the Amazon Redshift workforce and relies in New York. He’s a Core Workforce member of the open supply PostgreSQL undertaking and an energetic open supply contributor, together with PostgreSQL and the pgvector undertaking.
Jonathan Katz is a Principal Product Supervisor – Technical on the Amazon Redshift workforce and relies in New York. He’s a Core Workforce member of the open supply PostgreSQL undertaking and an energetic open supply contributor, together with PostgreSQL and the pgvector undertaking.
 Satesh Sonti is a Sr. Analytics Specialist Options Architect based mostly out of Atlanta, specialised in constructing enterprise knowledge platforms, knowledge warehousing, and analytics options. He has over 19 years of expertise in constructing knowledge property and main complicated knowledge platform applications for banking and insurance coverage shoppers throughout the globe.
Satesh Sonti is a Sr. Analytics Specialist Options Architect based mostly out of Atlanta, specialised in constructing enterprise knowledge platforms, knowledge warehousing, and analytics options. He has over 19 years of expertise in constructing knowledge property and main complicated knowledge platform applications for banking and insurance coverage shoppers throughout the globe.